前言
ORM,即Object-Relational Mapping(对象关系映射),它的作用是在关系型数据库和业务实体对象之间作一个映射,这样,我们在具体的操作业务对象的时候,就不需要再去和复杂的SQL语句打交道,只需简单的操作对象的属性和方法。下面是一个示例。通过使用 ORM,我们只需要操作 Author 和 Blog 对象,而不用操作相关的数据库表。这里主要介绍一下 Django ORM 的相关使用。
优缺点
使用 ORM 最大的优点就是快速开发,让我们将更多的精力放在业务上而不是数据库上,下面是 ORM 的几个优点
- 隐藏了数据访问细节,使通用数据库交互变得简单易行。同时 ORM 避免了不规范、冗余、风格不统一的 SQL 语句,可以避免很多人为的 bug,方便编码风格的统一和后期维护。
- 将数据库表和对象模型关联,我们只需针对相关的对象模型进行编码,无须考虑对象模型和数据库表之间的转化,大大提高了程序的开发效率。
- 方便数据库的迁移。当需要迁移到新的数据库时,不需要修改对象模型,只需要修改数据库的配置。
ORM 的最令人诟病的地方就是性能问题,不过现在已经提高了很多,下面是 ORM 的几个缺点
- 性能问题
- 自动化进行数据库关系的映射需要消耗系统资源
- 程序员编码
- 在处理多表联查、where 条件复杂的查询时,ORM 可能会生成的效率低下的 SQL
- 通过 Lazy load 和 Cache 很大程度上改善了性能问题
- SQL 调优,SQL 语句是由 ORM 框架自动生成,虽然减少了 SQL 语句错误的发生,但是也给 SQL 调优带来了困难。
- 越是功能强大的 ORM 越消耗内存,因为一个 ORM Object 会带有很多成员变量和成员函数。
- 对象和关系之间并不是完美映射
一般来说 ORM 足以满足我们的需求,如果对性能要求特别高或者查询十分复杂,可以考虑使用原生 SQL 和 ORM 共用的方式
Django ORM
在 Django 框架中集成了 ORM 模块,我们来看下具体的使用,部分内容会给出基于 MySQL 的 SQL 语句。
Manager
在创建完 Model 对象之后,Django 会自动为其关联一个 Manager 对象,该对象是 Model 进行数据库操作的接口。默认的 Manager 对象名称为 objects,下面是使用 Manager 进行增删改查的一个示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21def save_blog():
# 使用 get 检索数据时,如果数据不存在,会报 DoesNotExist 错误
# 可以使用 Blog.objects.all().filter(id=1).first() 方法
author = Author.objects.get(id=1)
blog = Blog(title='blog2', content='blog2', author=author)
blog.save()
def update_blog():
blog = Blog.objects.all().get(id=2)
blog.title = 'change_title'
blog.save()
def delete_blog():
blog = Blog.objects.all().filter(id=2).first()
if blog is not None:
blog.delete()
def fetch_blog():
blogs = Blog.objects.all()
for blog in blogs:
print blog
我们可以自定义 Manager 的名称,如下所示:1
2
3
4
5
6
7from django.db import models
class Person(models.Model):
#...
people = models.Manager()
Person.people.all()
同时我们也可以定义自己的 Manager,为 Manager 加上一些额外的功能,下面的示例会为 Author 添加上所写 Blog 数量信息:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33class AuthorManager(models.Manager):
def with_blog_counts(self, **kwargs):
from django.db import connection
cursor = connection.cursor()
condition = ''
if kwargs.has_key('id'):
condition = 'a.id = %s and ' % kwargs['id']
query = '''
SELECT a.id, a.name, COUNT(b.id)
FROM orm_author a LEFT JOIN orm_blog b
ON a.id = b.author_id
WHERE %s TRUE
GROUP BY a.id
''' % condition
cursor.execute(query)
result_list = []
for row in cursor.fetchall():
author = self.model(id=row[0], name=row[1])
author.blog_count = row[2]
result_list.append(author)
return result_list
class Author(models.Model):
name = models.CharField(max_length=50)
objects = AuthorManager()
authors = Author.objects.with_blog_counts(id=2)
for author in authors:
print author.name, author.blog_count
另外我们也可以为 Model 指定多个 Manager1
2
3class Author(models.Model):
manager = models.Manager()
manager2 = AuthorManager()
QuerySet
从数据库中查询出来的结果一般是一个集合,这个集合称为 QuerySet。QuerySet 有两种来源:通过 Manager 的方法获取、通过 QuerySet 自身的方法获得。Manager 的查询方法和 QuerySet 的方法大部分同名、同意(Manager的就是基于 QuerySet 的实现的),例如 filter, exclude等,但两者也有不同的方法,例如 Manager 的 create、get_or_create,QuerySet 的 delete 等。
基本查询
下面是 QuerySet (也是 Manager的)的几个基本的查询方法
all() - 获得数据库中所有实例的一个 QuerySet
1
2
3
4Blog.objects.all()
# 对应SQL
# SELECT `orm_blog`.`id`, `orm_blog`.`author_id`, `orm_blog`.`title`, `orm_blog`.`content`
# FROM `orm_blog`()filter(**kwargs) - 返回满足查询条件的 QuerySet
1
2
3
4Blog.objects.filter(title='blog2')
# 对应 SQL
# SELECT `orm_blog`.`id`, `orm_blog`.`author_id`, `orm_blog`.`title`, `orm_blog`.`content`
# FROM `orm_blog` WHERE `orm_blog`.`title` = 'blog2'exclude(**kwargs) - 获得不满足查询条件的 QuerySet
1
2
3
4Blog.objects.exclude(title='blog2')
# 对应 SQL
# SELECT `orm_blog`.`id`, `orm_blog`.`author_id`, `orm_blog`.`title`, `orm_blog`.`content`
# FROM `orm_blog` WHERE NOT (`orm_blog`.`title` = 'blog2')get(**kwargs) — 从数据库中获得一个匹配的结果(一个实例),如果没有匹配结果或者匹配结果大于一个都会报错
字段查询
在前面的 filter、exclude 和 get 方法中,我们需要传入参数作为选择条件: title='blog2',这个就是字段查询。字段查询的格式如下1
field__lookuptype=value # 中间是两个下划线
lookuptype 的类型有下面几种
- exact 精确匹配,默认的 lookup type。上面的
title='blog2'就相当于title__exact='blog2' - gt : 大于
- gte : 大于等于
- lt : 小于
- lte :小于等于
- in : in
- contains : 包含,区分大小写 -
a LIKE BINARY '%b%' - icontains : 包含,不区分大小写 -
a LIKE '%b%' - iexact : 大小写不敏感的精确匹配 -
a LIKE 'b' - startswith : 匹配开头,区分大小写 -
a LIKE BINARY 'b%' - istartswith : 匹配开头,不区分大小写 -
a LIKE 'b%' - endswith : 匹配结尾,区分大小写 -
a LIKE BINARY '%b' - iendswith : 匹配结尾,不区分大小写 -
a LIKE '%b'
我们还可以进行关联查询,下面的例子是查询所有 author name 为 zjk 的 blog,1
2
3
4
5
6blogs = Blog.objects.filter(author__name='zjk')
# SQL:
# SELECT `orm_blog`.`id`, `orm_blog`.`author_id`, `orm_blog`.`title`, `orm_blog`.`content`
# FROM `orm_blog` INNER JOIN `orm_author` ON (`orm_blog`.`author_id` = `orm_author`.`id`)
# WHERE `orm_author`.`name` = 'zjk'
限制 QuerySet
有时候我们并不需要获取查询集的全部数据,而只需要一个子集,一个常见的场景就是进行分页查询。使用 Python 的切片语法可以限制 QuerySet 的实例数量,ORM 会将翻译成 SQL 的 LIMIT 和 OFFSET 子句,下面是几个例子:
放回 QuerySet 的前 5 个元素
1
2
3
4
5blogs = Blog.objects.all()[:5]
# SQL:
# SELECT `orm_blog`.`id`, `orm_blog`.`author_id`, `orm_blog`.`title`, `orm_blog`.`content`
# FROM `orm_blog` LIMIT 5返回 QuerySet 的第 6-10 个元素
1
2
3
4
5blogs = Blog.objects.all()[5:10]
# SQL:
# SELECT `orm_blog`.`id`, `orm_blog`.`author_id`, `orm_blog`.`title`, `orm_blog`.`content`
# FROM `orm_blog` LIMIT 5 OFFSET 5使用切片的 step 参数,下面代码返回第 1、3、5、7、9 个元素
1
2
3
4
5blogs = Blog.objects.all()[:10:2]
# SQL:
# SELECT `orm_blog`.`id`, `orm_blog`.`author_id`, `orm_blog`.`title`, `orm_blog`.`content`
# FROM `orm_blog` LIMIT 10如果只要访问一个元素,可以直接用索引来访问:
1
2
3
4
5blog = Blog.objects.all()[2]
# SQL:
# SELECT `orm_blog`.`id`, `orm_blog`.`author_id`, `orm_blog`.`title`, `orm_blog`.`content`
# FROM `orm_blog` LIMIT 1 OFFSET 2
Lazy load
QuerySet 是惰性加载的,创建查询集不会访问数据库,只有查询集需要求值时,才会真正运行这个查询。在下面的例子中只有执行 print q 才会真正的去查询数据库。1
2
3
4
5
6
7
8
9q = Blog.objects.filter(title='blog2')
q = q.filter(content='blog2')
q = q.exclude(id=3)
# 执行下面的语句才会真正访问数据库
print q
# SQL:
# SELECT `orm_blog`.`id`, `orm_blog`.`author_id`, `orm_blog`.`title`, `orm_blog`.`content` FROM `orm_blog`
# WHERE (`orm_blog`.`title` = 'blog2' AND `orm_blog`.`content` = 'blog2' AND NOT (`orm_blog`.`id` = 3)) LIMIT 21
关联对象也是惰性加载,只有用到了关联对象的值才会访问数据库1
2
3
4
5
6
7
8
9
10blog = Blog.objects.filter(id=3).first()
print blog.title
# 只有执行下面的语句才会访问数据库获取 author 的值,也就是执行第二条 SQL
print blog.author.name
# SQL:
# SELECT `orm_blog`.`id`, `orm_blog`.`author_id`, `orm_blog`.`title`, `orm_blog`.`content`
# FROM `orm_blog` WHERE `orm_blog`.`id` = 3 ORDER BY `orm_blog`.`id` ASC LIMIT 1
#
# SELECT `orm_author`.`id`, `orm_author`.`name` FROM `orm_author` WHERE `orm_author`.`id` = 1
一般来说只要用到了 QuerySet 以及里面对象的信息,就会访问数据库。下面是文档中给出的几种会对查询集求值的情况:
- 迭代:在首次迭代查询集时会执行数据库查询
- 切片(限制查询集):对查询集执行切片操作时,指定 step 参数
- 序列化/缓存
- repr:对查询集调用 repr 函数
- len:对查询集调用 len 函数
- list: 对查询集调用 list() 方法强制求值
- bool:测试一个查询集的布尔值,例如使用bool(), or, and 或者 if 语句都将导致查询集的求值
缓存
每个 QuerySet 都包含一个缓存来最小化对数据库的访问,下面是一个示例:1
2
3
4
5
6
7
8# 下面代码会访问两次数据库
print [blog.title for blog in Blog.objects.all()]
print [blog.content for blog in Blog.objects.all()]
# 下面代码只会访问一次数据库
blogs = Blog.objects.all()
print [blog.title for blog in blogs]
print [blog.content for blog in blogs]
在一个新的 QuerySet 中,缓存为空。当首次对 QuerySet 的所有实例进行求值时,会将查询结果保存到 QuerySet 的缓冲中。当再访问该 QuerySet 时,会直接从缓冲中取数据。下面是一个示意图:
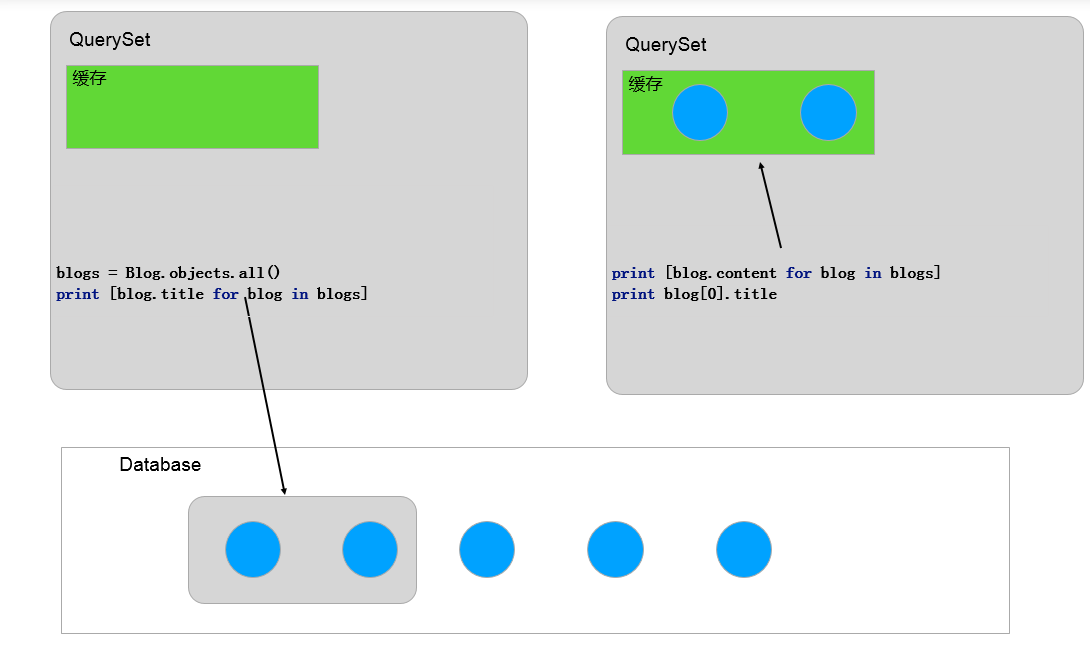
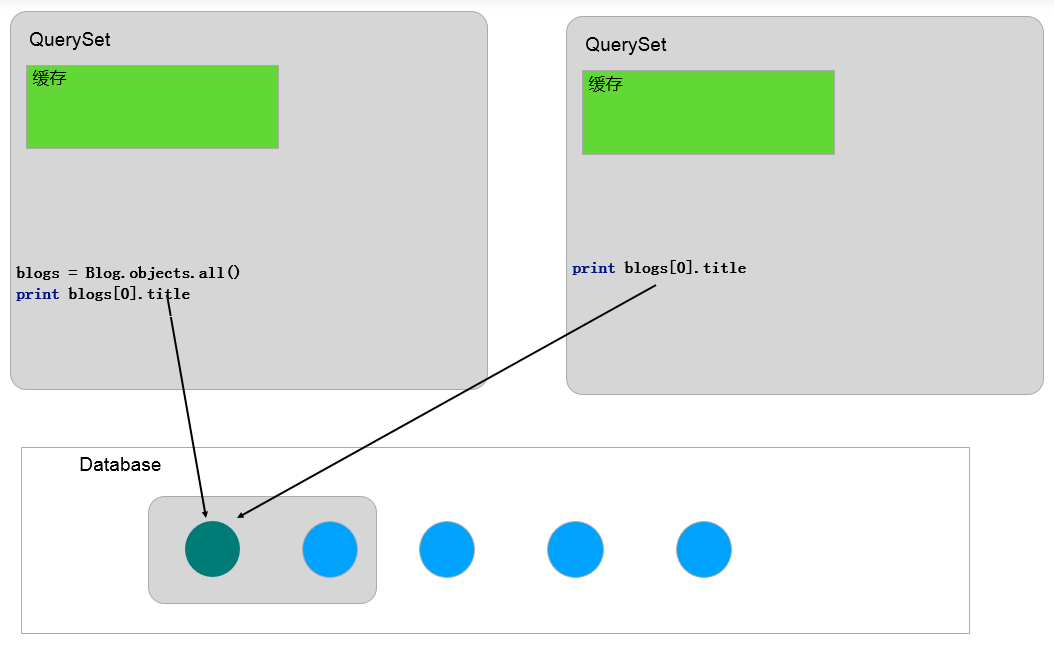
如果只对 QuerySet 的部分实例(query_set[5], query_set[0:10])进行求值,首先会到 QuerySet 的缓冲中查找是否已经缓存了这些实例,如果有就使用缓存值,如果没有就查询数据库,但是不会将查询结果保存到缓冲中。如下图所示:
如果 QuerySet 数量很大不希望被缓存,遍历时使用 iterator 方法:1
2
3blogs = Blog.objects.all()
for blog in blogs.iterator():
print blog.title
关联查询
在讲关联查询之前,首先看一下下面的一个示例。我们前面提到,关联实例是惰性加载的,因此对于下面的代码,每次 for 循环都要访问一次数据库,会严重影响性能。因此我们需要一次将 blog 以及 author 的信息全部取出来,这就是我们马上要讲的关联查询。1
2
3
4
5
6
7
8
9for blog in Blog.objects.all():
print blog.title, blog.author.name
# SQL:
# SELECT `orm_blog`.`id`, `orm_blog`.`author_id`, `orm_blog`.`title`, `orm_blog`.`content` FROM `orm_blog`
#
# SELECT `orm_author`.`id`, `orm_author`.`name` FROM `orm_author` WHERE `orm_author`.`id` = 1
# SELECT `orm_author`.`id`, `orm_author`.`name` FROM `orm_author` WHERE `orm_author`.`id` = 1.
# . . . . . .
关联查询就是在查询当前实例的同时,把其关联的实例数据也一块取出来。在下图中 orm_blog 通过一个外键和 orm_author 关联。关联大体上可以分为两种:
- 只有一个关联实例: 外键关联中包含外键的表、OneToOneField,例如下图中的 orm_blog 只与一个 orm_author 的实例关联
- 有多个关联实例:外键关联中不含外键的表、ManyToManyField,例如下图中的 orm_author 就与多个 orm_blog 实例关联
因此 Django ORM 中的关联查询也分两中 select_related(单关联实例) 和 prefetch_related(多关联实例)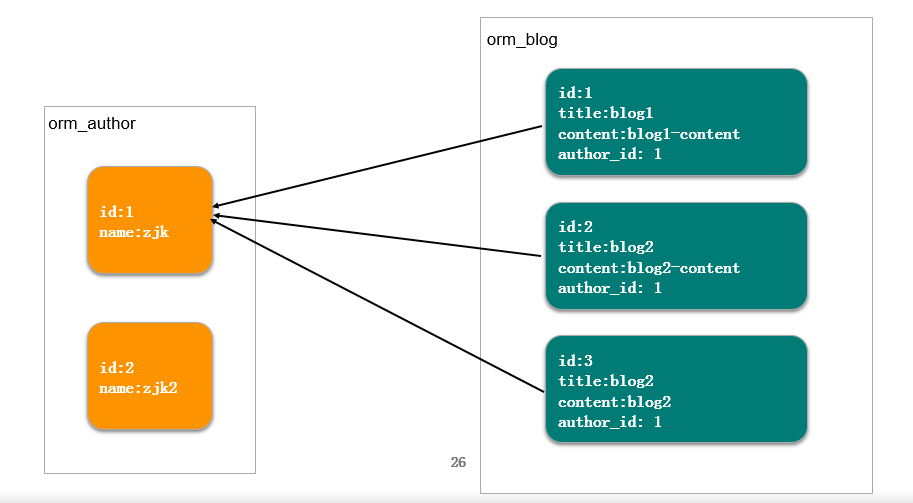
select_related
select_related 用来处理单关联实例的情况,适用于 ForeignKey 和 OneToOneField。在查询时,会对关联的表进行 join 操作,取出全部的信息,下面是一个示例:1
2
3
4
5
6
7blog = Blog.objects.select_related().filter(id=3).first()
print blog.id, blog.author.name
# SQL
# SELECT `orm_blog`.`id`, `orm_blog`.`author_id`, `orm_blog`.`title`, `orm_blog`.`content`, `orm_author`.`id`, `orm_author`.`name`
# FROM `orm_blog` INNER JOIN `orm_author` ON (`orm_blog`.`author_id` = `orm_author`.`id`)
# WHERE `orm_blog`.`id` = 3 ORDER BY `orm_blog`.`id` ASC LIMIT 1
下面是一个示意图:
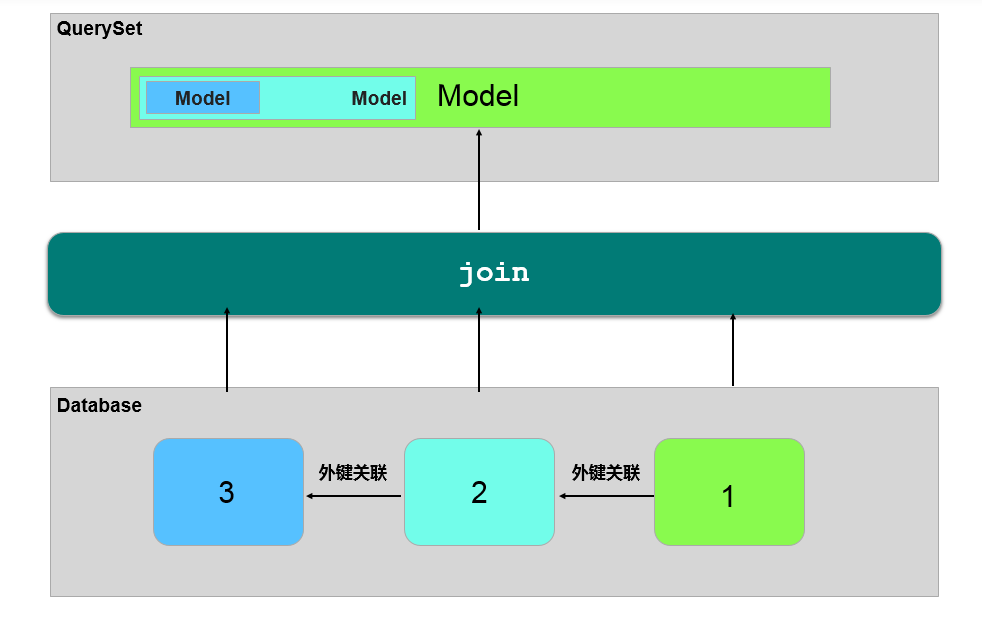
select_related 会沿着外键递归查询,例如上图中取表 1 的实例时,会沿着外键将表 3 的数据一块取出来。我们可以传入 depth 参数来指定递归的深度。
如果需要清除 QuerySet 上以前的 select_related 添加的关联字段,可以传入 None 做参数
prefetch_related
prefetch_related 主要适用于 OneTwoMany 和 ManyToManyField。和 select_related 类似,prefetch_related 在查询时会同时取出关联实例的值。与 select_related 不同的是 prefetch_related 不使用 JOIN 方式来查询数据库,而是分别查每个表,最后使用 Python 来实现 JOIN 操作。下面是一个示例:1
2
3
4
5
6
7
8
9
10author = Author.objects.prefetch_related('blog_set').filter(name='zjk').first()
for blog in author.blog_set.all():
print blog
# SQL:
# SELECT `orm_author`.`id`, `orm_author`.`name` FROM `orm_author`
# WHERE `orm_author`.`name` = 'zjk' ORDER BY `orm_author`.`id` ASC LIMIT 1
#
# SELECT `orm_blog`.`id`, `orm_blog`.`author_id`, `orm_blog`.`title`, `orm_blog`.`content`
# FROM `orm_blog` WHERE `orm_blog`.`author_id` IN (1)
下面是一个示意图:
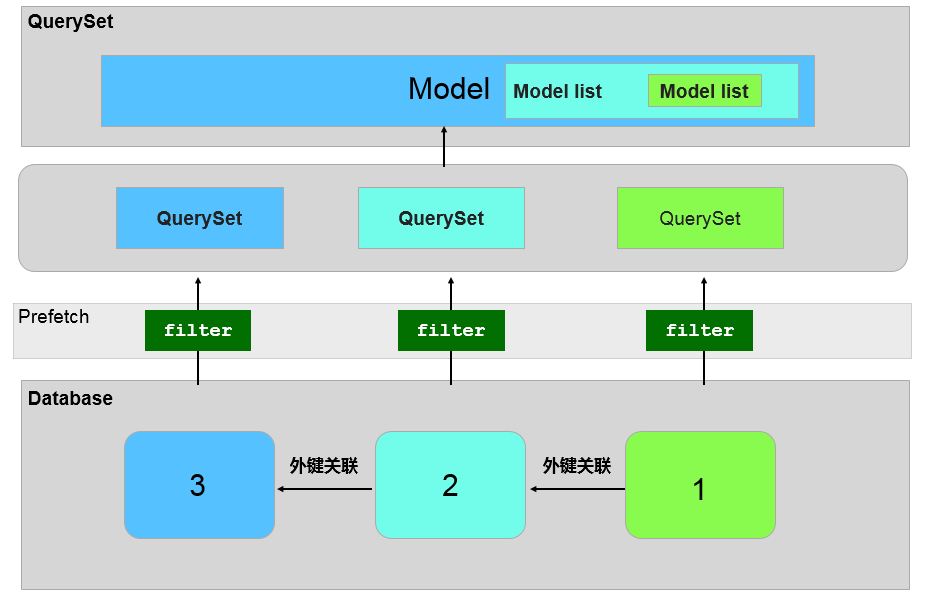
如果查询出关联对象的 QuerySet 之后,再对该 QuerySet 执行查询条件,会使该 QuerySet 失效(也就是需要再次访问数据库)。如果在查询关联对象时需要使用查询条件,可以使用 Prefetch 对象,下面是一个示例:
1 | from django.db.models import Prefetch |
Q 查询
在前面所讲的 filter 和 exclude 方法,对于传入的查询条件都是执行的 AND 操作,如果我们需要对查询条件执行 OR 操作,例如查询 blog 表中 title=‘blog1’ 或者 title=‘blog2’ 的实例,就需要用到 Q 查询。Q 查询支持使用 |、&、~ 操作符,分别对象查询条件的 OR、AND 和 NOT 操作。下面是一个示例:1
2
3
4
5
6
7
8
9from django.db.models import Q
blogs = Blog.objects.filter(Q(id=10) | Q(title='blog2'))
for blog in blogs:
print blog
# SQL:
# SELECT `orm_blog`.`id`, `orm_blog`.`author_id`, `orm_blog`.`title`, `orm_blog`.`content`
# FROM `orm_blog` WHERE (`orm_blog`.`id` = 10 OR `orm_blog`.`title` = ‘blog2')
F 查询
F 查询主要用来处理表中字段之间的比较,例如查询 blog 表中 title=conent 的记录。同时 F 查询还支持计算(加减乘除)。下面是一个示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17from django.db.models import F
blogs = Blog.objects.filter(title=F('content'))
for blog in blogs:
print blog
# SQL:
# SELECT `orm_blog`.`id`, `orm_blog`.`author_id`, `orm_blog`.`title`, `orm_blog`.`content`
# FROM `orm_blog` WHERE `orm_blog`.`title` = (`orm_blog`.`content`)
blogs = Blog.objects.filter(title=F('content')+2)
for blog in blogs:
print blog
# SQL:
# SELECT `orm_blog`.`id`, `orm_blog`.`author_id`, `orm_blog`.`title`, `orm_blog`.`content`
# FROM `orm_blog` WHERE `orm_blog`.`title` = ((`orm_blog`.`content` + 2))
values 和 values_list
有些时候我们不需要获取实例中所有的数据,而只需要获得几个字段的数据即可,使用 values 和 values_list 可以指定检索的字段。values 会返回一个 dict 数组,而 values_list 会返回 list 数组。下面是一个例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14blogs = Blog.objects.filter(id=5).values('title')
print blogs
# <QuerySet [{u'title': u’blog2'}]>
blogs = Blog.objects.filter(id=5).values_list('title')
print blogs
# <QuerySet [(u’blog2',)]>
blogs = Blog.objects.filter(id=5).values_list('title', flat=True)
print blogs
# <QuerySet [u’blog2']>
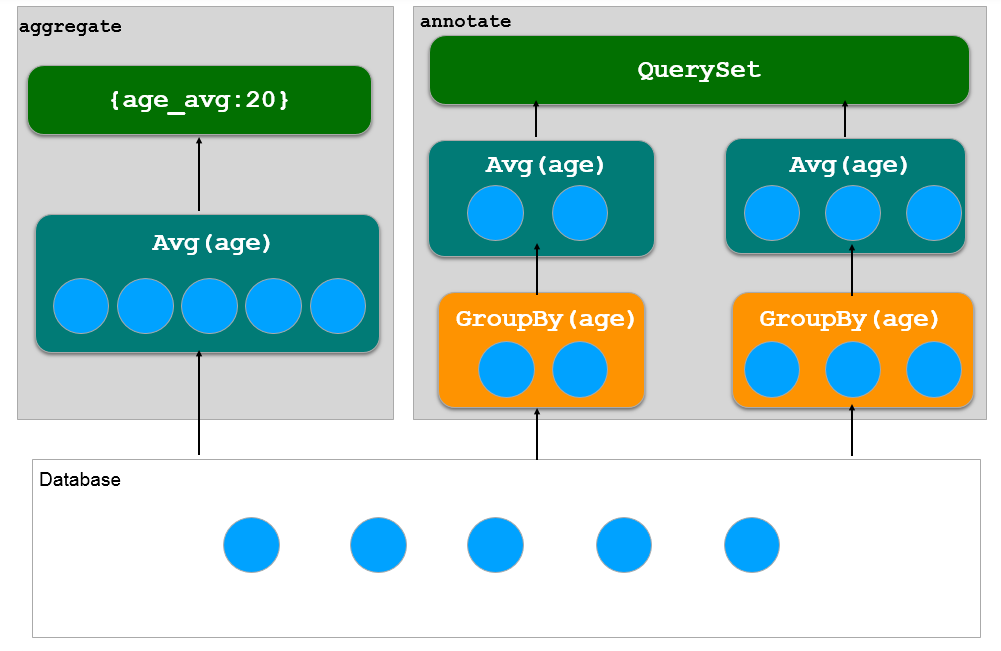
aggregate 和 annotate
通过 aggregate 和 annotate 可以使用 SQL 的聚合函数,例如 SUM、COUNT、MIN 等。aggregate: 针对所有记录调用聚合函数,返回一个 dict 对象,下面是使用示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15from django.db.models import Min
from django.db.models import Sum
result = Blog.objects.aggregate(Min('id'))
print result
# {u'id__min': 3L}
# SELECT MIN(`orm_blog`.`id`) AS `id__min` FROM `orm_blog`
# 自定义属性名
result = Blog.objects.aggregate(total=Sum('id'))
print result
# {'total': Decimal(‘657')}
# SELECT SUM(`orm_blog`.`id`) AS `total` FROM `orm_blog
annotate 先使用 groupby 分组,然后对于每组再调用聚合函数,返回 QuerySet 对象。 annotate 默认按照 id 进行分组,如果需要按其他字段分组,要结合 values /values_list 方法。下面是使用示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24#认按照 id 进行分组
blogs = Blog.objects.annotate(Count('title'))
for blog in blogs:
print blog.title__count
# SELECT `orm_blog`.`id`, `orm_blog`.`author_id`, `orm_blog`.`title`, `orm_blog`.`content`,
# COUNT(`orm_blog`.`title`) AS `title__count` FROM `orm_blog` GROUP BY `orm_blog`.`id` ORDER BY NULL
# 使用 values 方法,会按照 values 中传入的属性分组
blogs = Blog.objects.values('title').annotate(Count('title'))
for blog in blogs:
print blog['title__count']
# SELECT `orm_blog`.`title`, COUNT(`orm_blog`.`title`) AS `title__count` FROM `orm_blog`
# GROUP BY `orm_blog`.`title` ORDER BY NULL
blogs = Blog.objects.values('title', 'content').annotate(Count('title'))
for blog in blogs:
print blog['title__count']
# SELECT `orm_blog`.`title`, `orm_blog`.`content`, COUNT(`orm_blog`.`title`) AS `title__count`
# FROM `orm_blog` GROUP BY `orm_blog`.`title`, `orm_blog`.`content` ORDER BY NULL
下图是 aggregate 和 annotate 的比较:
extra
如何一些查询比较复杂可以考虑使用 extra 方法。extra 能在 ORM 生成的 SQL 子句中注入 SQL 代码,语法格式如下:1
2# 至少保证一个参数不为空
extra(select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
select:在 select 子句中插入 SQL 代码
1
2
3
4
5
6
7
8
9
10
11blogs = Blog.objects.extra(select={
'is_one': ‘id=5'
})
# SELECT (id=5) AS `is_one`, `orm_blog`.`id`. . . . .
authors = Author.objects.extra(
select={
'blog_count' : 'select count(*) from orm_blog where orm_blog.author_id = orm_author.id'
}
)
# SELECT (select count(*) from orm_blog where orm_blog.author_id = orm_author.id) AS `blog_count` . . .select_params: 设置 select 参数
1
2
3
4
5
6
7blogs = Blog.objects.extra(
select={
'a': '%s'
},
select_params=(‘id=1',)
)
# SELECT ('id=1') AS `a` . . . . .where: 在 where 子句中插入 SQL 代码
1
2
3
4blogs = Blog.objects.extra(
where=['id=4 or id=5']
)
# SELECT . . . . . . FROM `orm_blog` WHERE (id=4 or id=5)params: 为 where 设置参数
1
2
3
4
5blogs = Blog.objects.extra(
where=['id=%s'],
params=(1,))
# SELECT . . . . . . FROM `orm_blog` WHERE (id=1)tables: 在 FROM 子句中插入 table 名称
1
2
3
4blogs = Blog.objects.extra(
tables=['orm_author', 'auth_group']
)
# SELECT . . . . . . FROM `orm_blog` , `orm_author` , `auth_group`order_by:在 order_by 子句中插入排序字段
1
2
3
4
5# - 表示倒序
blogs = Blog.objects.extra(
order_by=['-id', 'title']
)
# SELECT . . . . . . FROM `orm_blog` ORDER BY `orm_blog`.`id` DESC, `orm_blog`.`title` ASC
原始 SQL 查询
使用 Manager 的 raw 方法可以用于原始的 SQL 查询,并返回 Model 的实例:1
2
3blogs = Blog.objects.raw('select * from orm_blog')
for blog in blogs:
print blog.id , blog.title
如果 SQL 中没有获取某个字段,那么会惰性加载该字段1
2
3
4
5
6
7
8
9
10# 没有取 title,在后面使用时会访问数据库
blogs = Blog.objects.raw('select id from orm_blog')
for blog in blogs:
print blog.id
print blog.title
# select id from orm_blog
# SELECT `orm_blog`.`id`, `orm_blog`.`title` FROM `orm_blog` WHERE `orm_blog`.`id` = 3
# SELECT `orm_blog`.`id`, `orm_blog`.`title` FROM `orm_blog` WHERE `orm_blog`.`id` = 4
#. . . .
一些优化
如果只需要判断实例是否存在,使用 exists 更高效
1
2
3
4
5blogs = Blog.objects.filter(id=5)
if blogs.exists():
print 'record exist’
# SELECT (1) AS `a` FROM `orm_blog` WHERE `orm_blog`.`id` = 5 LIMIT 1如果只需要得到实例的数量,使用 count 函数
1
2
3
4blogs = Blog.objects.filter(id=5)
print blogs.count()
# SELECT COUNT(*) AS `__count` FROM `orm_blog` WHERE `orm_blog`.`id` = 5