内存访问粒度
如果没有深入的了解内存方面的东西, 我们可能会认为内存不过是简单的字节数组, 例如下面的形式
但是实际上, 计算机的处理器并不是以单个字节块为单位读写内存, 而是以2个,4个,8个,甚至16或者32个字节块为单位读写内存,如下图所示 我们将处理器访问内存单元的大小叫做其内存访问的粒度.
知道上面这一点很重要, 这也是C语言alignment的基础.
alignment 基本知识
为了说明对齐的基本原则, 下面举一个例子: 该示例很简单首先我们从地址0读取4个字节到处理器的register(寄存器), 然后我们从地址1读取4个字节到同一个寄存器.
首先我们看一下当处理器的访问粒度为1时的情况: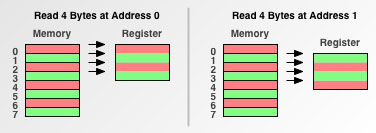
在这种情况下, 从地址0开始读和从地址1开始需要访问四次内存其所需的时间是相同的. 下面再看一下当处理器的内存访问粒度为2时的情况:
在这种情况下, 每次访问内存可以读取两个字节, 所以当从地址0 开始读时, 只需要访问两次内存, 这比单字节粒度减少了一半的时间. 但是当从地址1开始读时, 却需要访问三次内存, 第一次读[0,1]两个位置的字节, 第二次读[2,3]两个位置的字节,第三次读[4,5]两个位置的字节. 之所以出现这种情况是因为开始读取的位置(即1)没有位于处理器内存访问的边界上(当粒度为2时, 边界为0, 2, … , 2n), 所以需要额外的操作. 而这种地址就是所说的未对齐的地址(unaligned address).
最后我们再来看一下当内存访问粒度为4时的情况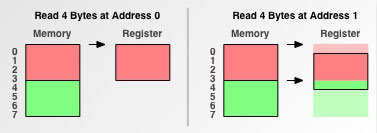
当从地址0开始读时, 只需要一次内存访问, 而从地址1(未对齐的地址)开始读时需要两次内存访问.
通过上面的示例我们可以看到从未对齐位置访存要比从对齐位置访问多一次访存的操作, 然而除了多了一次访问之外, 我们还要注意到未对齐访存时会取到一些多余的数据, 处理器还要将这些多余的数据去除, 如下图所示: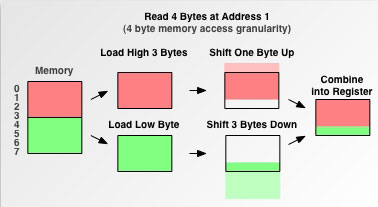
从上面可以看到当读取了第一个内存块之后需要移除地址0的字节, 当读取了第二个内存块后要移除地址6-8的字节, 这很大程度上增加了处理器的负担.
内存对齐(memory alignment)
大多数CPU都要求位于内存中的变量和对象有一个特殊的起始位置(或者偏移 offset), 例如32位的处理器要求一个4字节整型在内存中的地址(第一个字节的地址)能被4整除, 我们就可以将这种要求(requirement)称为”memory alignment”. 当向内存中存入一个变量(variable)时, 此数据的地址应该是该数据alignmengt的整数倍.
基本类型对齐
对于基本类型来说, 它的alignment值和其所占的长度有关, 一般来说, 其alignment值就是其所占的字节数.
1 |
|
下面是基本的对齐原则:

在不同的机器上对其原则是不同的, 所以要根据具体的机器来, 上面所说的地址的最低一位为0, 就是起始位置必须是2的倍数, 最低两位为0, 则是起始位置必须是4的倍数.
结构体对齐
默认对齐方式
基本对齐原则如下:
- 结构体对齐值: 其成员中自身对齐值最大的那个值
- 结构体中成员的对齐值: 成员自身对齐值和结构体对齐值中较小的那个
- 结构体的大小为结构体对齐值的整倍数
- 结构体一般会通过插入空位的(padding)方式来满足上面的原则
比如下面的结构体:1
2
3
4
5struct mystruct {
char c;
int i;
short s;
};
在这个结构体中, c占1个字节, i占4个字节, s占两个字节, 所以mystruct的alignment值是4, 此时该结构体占12个字节, 下面是示意图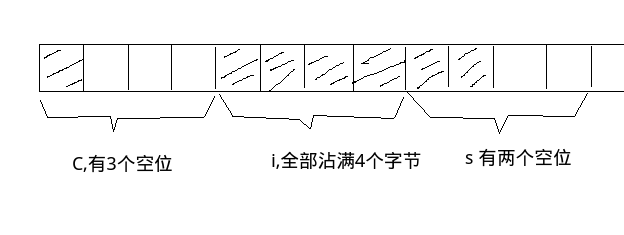
我们将上面的结构修改一下, 将s和i的顺序换一下1
2
3
4
5struct mystruct{
char c;
short s;
int i;
};
那么此时该结构体所占的字节为8, 下面是内存示意图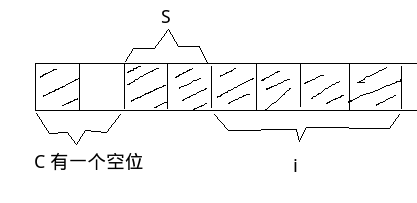
所以为了尽量减少结构体中的空位, 我们应该合理的安排结构体中成员的顺寻.
如果结构体中包含结构体, 比如下面的代码:1
2
3
4
5
6
7
8
9struct mystruct1{
char c;
double d;
};
struct mystruct2{
char c;
struct mystruct1 st1;
};
在这种情况下, 我们其实可以将mystruct1当成一个对齐值为8, 长度为16的基本类型处理, 只不过对齐值和所占的字节数是不固定的.
指定对齐值的大小
方法一: #pragma pack(value)
我们可以通过使用#pragma pack(value) 来指定对齐值的大小. 看下面的代码:1
2
3
4
5
6
7
struct mystruct {
char c;
int i;
short s;
};
#pragma pack(1)将结构体及其成员的对齐值设为1, 也就是说结构体中的成员可以从任意的地址位置开始, 此时mystruct的大小为7.
_注意如果pack中的value大于结构体原先的对齐值, 那么结构体仍然采用原先的对应值. 而结构体中每个数据成员的对齐,
按照#pragma pack指定的数值和这个数据成员自身长度中,比较小的那个进行. _
方法二:__attribute__((aligned(n)))
__attribute__((aligned(n))): 让所作用的结构成员对齐在n字节自然边界上。如果结构中有成员的长度大于n,则按照最大成员的长度来对齐。__attribute__((packed)):取消结构在编译过程中的优化对齐,按照实际占用字节数进行对齐。
1 | // 对齐值为16 |
华丽的分割线
- 实际的运行效率
其实现在的计算机已经能很好没有对齐的情况了, 所以我们在一般的机器上运行时, 即使没有对齐也不会有很大的效率问题,
1 |
|
使用gcc编译代码1
gcc -DRUNS=400000000 -o time test_time.c
然后执行会发现两者运行速度几乎是相同的. 但是在一些老的机器或者协处理器上内存对齐对速度还是有一定影响的.
参考文章